How to Create a Metadata File Help Page
In order to analyze your data, we require a Meta Data file as a .csv which contains information about your data and groups
The link below provides a sample Metadata file we have created for demonstration purposes.
- What is a Metadata File?
- How do I include Batch Effects or Repeated Measures?
- Why would I use multiple Metadata Files?
What is a Metadata File?
The Metadata File is a comma seperated values file (.csv) with a minimum of 2 columns.
- The 1st column is required to be named ‘File Name’ and needs to contain the
names of the untargeted metabolomic data files to be used in the analysis.
- All additional columns are covariates associated with your untargeted metabolomic data files, however only
3 can be used at a time for analysis in the free version.
-
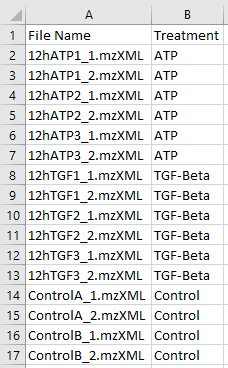
The image below displays the sample metadata file named 'sample_metadata.csv'. A metadata file can
be named anything as long as it is a ‘.csv’ file extension.
-
This Metadata file has 16 samples that are defined under the 1st column, 'File Name'
(required). These are the untargeted metabolomic files that will be used in an
analysis.
-
The 2nd column is named 'Treatment', this column defines the grouping information for each
of the 16 samples. In this example, the samples belong to 1 of 3 groups, ATP, TGF-Beta, or
Control. Thus, an analysis using this metadata file will look for features that are
significantly different between these 3 groups.
- Note that the 2nd column is named 'Treatment' in the example but can be named anything.
If you need additional assistance in creation of you metadata file, please do not hesitate to contact us.
How do I include Batch Effects or Repeated Measures?
If your experiment collected measurements on subjects multiple times. You can analyze your data using the ‘Group Comparison with Repeated Measures’ study design. This will take into account samples coming from the same subject multiple times.
If your experiment collected and ran samples in batches(different times). You can analyze your data using the ‘Group Comparison with Batch Adjustment ’ study design. This will take into account samples being run at different times.
-
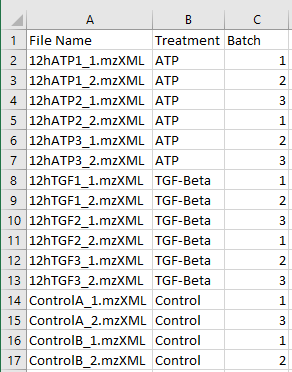
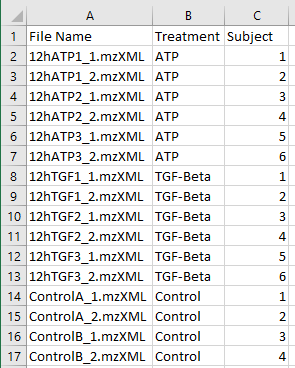
The images below display the sample metadata files for the batch and the repeated measures.
-
These files look identical to the base sample data except for 1 additional column. This column is
required for both the batch and the repeated measures.
-
In the example on the left the additional column is named 'Batch' and indicates which batch each sample came from.
-
In the example on the right the additional column is named 'Subject' and indicates which subject each sample came from.
Why would I use multiple Metadata Files?
Our software allows for multiple metadata files to be uploaded per dataset. In order to test multiple hypothesis on the same dataset
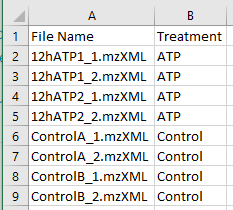
The file below shows another sample metadata file that was editted from the base metadata file. The difference is that there are now only 8 samples from 2 different treatments. Therefore, an analysis using this metadata file will look for features that are significantly different between the 2 groups of ATP and Control.
This metadata file can be uploaded and used with the full sample dataset of 16.
The following image displays 3 uploaded metadata files for a single data set on the ‘Upload Data’ page.
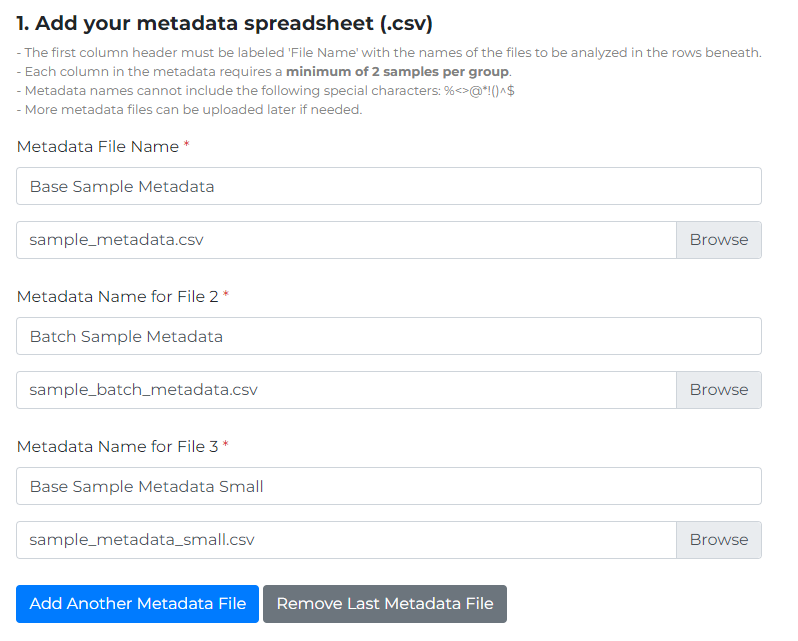
If you have any issues please do not hesistate to contact us
Continue to the Uploading a Dataset Guide or go straight to Starting a New Analysis

